Quantum mechanics is as abstract as anything can be. Quantum mechanics is what your evolutionarily developed neural structure is not prepared to deal with directly. How do you deal with it? Abstract mathematics. Okay, let's begin quantum mechanics.
以上是斯坦福大学量子力学课程中老师给出的一段建议。在接触量子计算时,我们常常会接触一些难以想象和可视化的概念。想要理解这些概念,就需要我们构建全新的思维模式。然而,正是这些“悬浮”的概念(例如叠加态、纠缠态),构成了量子计算的“超能力”,使其可以解决经典计算无法解决的难题。为了使这种“超能力”尽快变成现实,业界一直致力于实现强大、可靠的真实量子计算机及其生态系统,而软件开发工具包(Software Development Kit,SDK)是其中一个关键组件。为了便于理解与使用,量子编程语言的SDK通常借鉴了经典计算中的概念和架构,并加以适应量子计算的特性。这就导致在具体实施的过程中,开发人员不仅会出现经典编程中常见的错误,也会由于思维上的差异造成一些全新的、与量子特性相关的错误,边界缺陷就是其中一种。今天为大家分享的是一篇发表于ISSTA 2024的论文UPBEAT: Test Input Checks of Q# Quantum Libraries,论文以微软Q#为研究对象,提出了一个能够检测由量子特性导致的边界缺陷的工具——UPBEAT,该论文由西北大学、利兹大学、康考迪亚大学、合肥工业大学合作完成并投稿。

研究背景
Q#是微软团队开发的一门高级量子编程语言,用于开发和运行量子算法。Q#的一个核心组件是开发工具包库(Development Kit Libraries),其中包含了丰富的操作以及与量子计算相关的数据类型,涵盖了经典数学、类型转换、错误诊断、量子纠错等功能。在使用Q#编写量子程序时,用户通常将其实现视为黑盒,并认为Q#的实现是足够健壮的。然而,与任何大型软件一样,Q#库中也可能存在许多错误。在Q#库中,一个常见的问题是缺乏或者存在错误的API输入检查(在本文中,这些缺陷被称为“边界缺陷”)。理想状态下,一个完备的库应该能够在早期输出有效的错误信息,以提示用户其输入不符合要求,帮助开发人员更好的调试和修改代码。
让我们通过一个例子来了解一下。

图1 一个潜在边界缺陷的Q#函数
图1中的代码是一个简化后的Q#函数,想要调用这个函数,需要传入三个参数:BigInt类型的func变量,Qubit[]类型的controlRegister变量和Qubit类型的target变量。在这个函数中,当量子比特数组controlRegister的长度为0时,调用内部的FastHadamard函数(第8行)将导致一个运行时错误。
Unhandled exception. System, argument out of range expectation: specified argument was out of the range of valid values.
可以看到,错误消息并没有直接指向变量controlRegister,也没有提供该变量的值是不合法的提示。当开发人员遇到这个运行时错误时,很有可能也是满脸问号,因为很难从中推断出问题到底出现在哪里。那么,想要生成触发该缺陷的测试用例,都需要满足哪些要求呢?
首先,需要为参数func和target传入合法的值,避免在进行第4行和第5行的输入检查时提前中断。
其次,需要为参数controlRegister传入触发该边界缺陷的值。
最后,由于不同的Q#模拟器对于这一API的实现是相同的,传统的差分测试无法检测到这一异常。因此,需要在Q#层面建立一个新的测试预言(test oracle)来捕获这种异常。
系统实现
图2展示了UPBEAT的整体流程。

图2 系统概述图
阶段1 以类型为引导的代码片段收集
首先,UPBEAT从API文档中提取API的具体信息,与经典编程语言类似,包括命名空间、输入和输出等。同时,UPBEAT从文档示例、Q#库的源代码以及GitHub上的开源Q#程序中收集代码片段。这些收集到的信息将被用于指导UPBEAT生成高质量的测试用例,并有助于发现潜在的边界缺陷。
阶段2 测试代码生成
在该阶段,UPBEAT拼接多个代码片段以获取测试代码(test code)。UPBEAT首先随机选择一个具有至少一个可调用函数的代码段作为起始点,然后根据约束条件逐步选择类型匹配的代码片段进行拼接,最终合成一个测试代码。
阶段3 测试输入数据生成
UPBEAT从API文档的自然语言描述和库源码的输入检查语句中提取约束条件,前者由GPT4完成,后者由一个基于正则解析的简易工具完成。随后,UPBEAT将输入生成的过程视为经典计算中的约束满足问题(Constraint Satisfication Problem, CSP)和量子计算中的量子状态建模,以生成合理或者不合理的变量值作为API的输入。与经典约束相关的值主要由Z3求解器进行求解,而在处理量子约束时,UPBEAT使用一个四元组<axis,result, probability, tolerance>来表示一个特定的量子状态,并通过计算旋转角度来改变对应变量(量子比特/量子比特数组)的值。
阶段4 测试用例合成
UPBEAT使用一个自定义的代码模板生成测试用例。该模板包含包括三个关键元素:(1)变量声明,(2)包含用于测试Q#库可调用的API调用语句的测试代码,以及(3)用于输出执行结果的诊断语句。
阶段5 测试用例执行
UPBEAT总共捕获四种可能的异常情况:BoundError、Inconsistency、Crash和Timeout。BoundError出现在UPBEAT检测到执行结果与预期不符的情况下,包括两种情况:(1)生成了包含有效输入(valid input)的测试用例,但捕获到抛错中断,或者(2)生成了包含无效输入(invalid input)的测试用例,但程序能够成功执行时。如果在差分测试期间观察到执行结果的不一致,则标记为Inconsistency。Crash和Timeout是两种常见的异常行为,可能在单个模拟器执行或差分测试中发生。
实验评估
在实验评估环节,UPBEAT生成了12K测试用例,在运行100小时内发现了20个边界缺陷,其中16个与API实现有关,4个是文档中的错误。14个缺陷已被修复,12个已被确认。
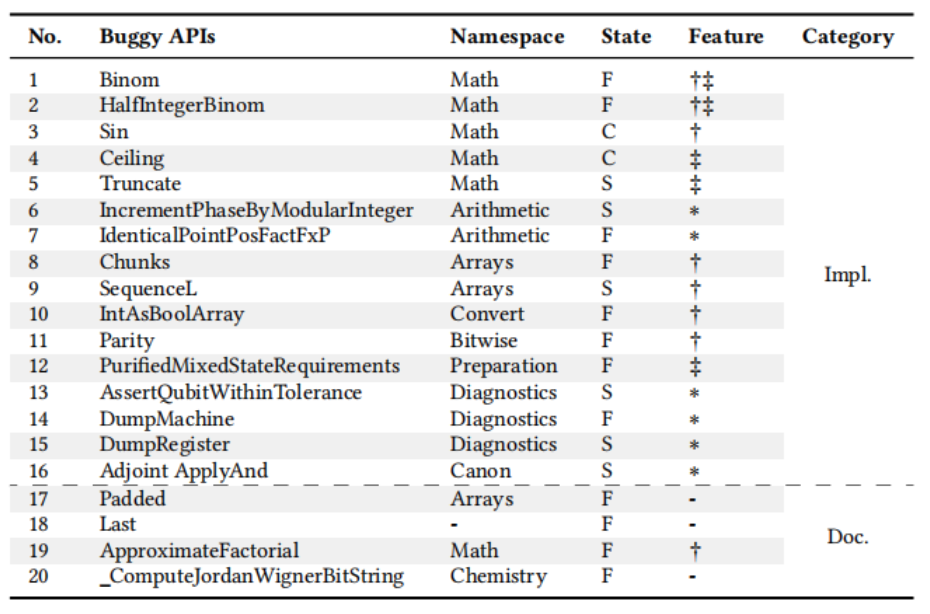
表1 UPBEAT检测到的缺陷
随后,本文使用6个基准工具以及2个UPBEAT的变体进行了对比实验。评估指标为代码覆盖率(插桩后库源码的代码覆盖率)以及异常行为的数目。
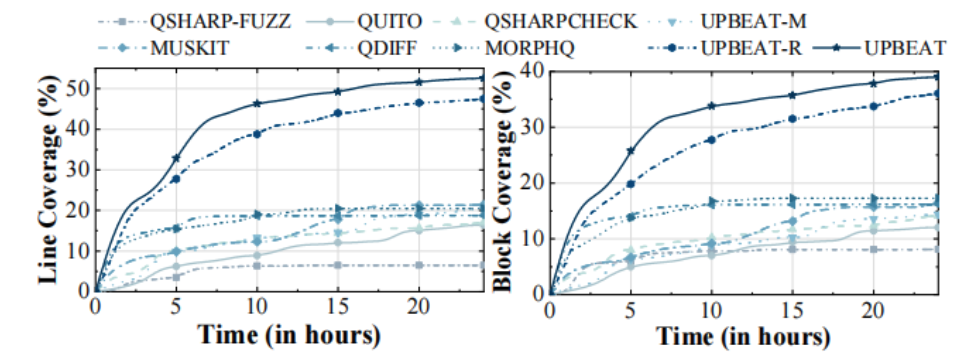
图3 代码覆盖率实验结果(左图为行覆盖率,右图为块覆盖率)
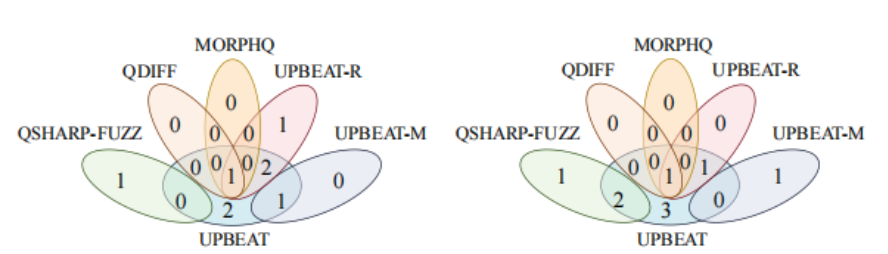
图4 异常数目实验结果(左图为使用Q#层面的测试预言的结果,右图为差分测试结果)
从图3中可以看到,在24小时的运行时间内,UPBEAT一直保持着最高的代码覆盖率,这得益于UPBEAT能够保证生成的测试用例是语法正确的,此外,基于经典约束和量子约束生成的API输入能够有效地触发新的代码分支。由图4可知,UPBEAT总共检测到13个潜在的异常行为,与其他对比工具相比至少增加了2倍。
为了评估UPBEAT提取约束的完整性和正确性,作者随机选择了10个Q#库并进行了手工验证,结果如表2所示。
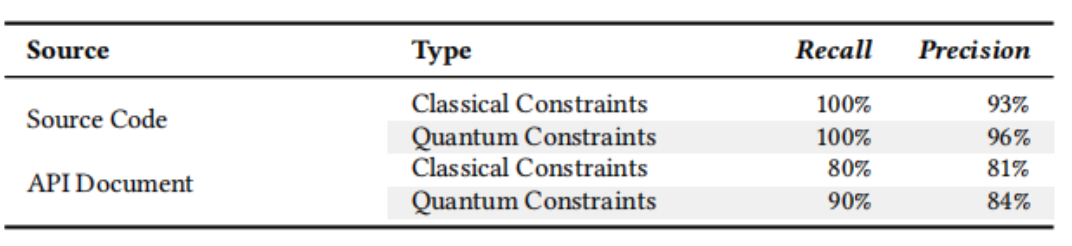
表2 约束截取的分析结果
UPBEAT从库源代码中识别出了所有API的约束,并成功地获取了80%的经典约束和90%的量子约束。该工具在从API源代码中提取约束的精度上达到了超过90%,而从API文档中提取约束的精度也超过80%。这些结果表明,大多数约束都能够被准确地提取出来。
本项目预计于五月份开源(https://github.com/NWU-NISL-Fuzzing/UPBEAT),欢迎大家前往讨论交流~
叶老师邮箱:gxye@nwu.edu.cn
投稿团队介绍:
西北大学汤战勇、叶贵鑫老师团队一直以来致力于编译器导向性模糊测试的研究工作,已在、ESEC/FSE2023上发表相关论文,分别为JS 引擎的标准一致性测试方法以及历史测试脚本驱动的编译器导向测试方法,在JS、JVM等主流编译器上发现200余个缺陷,已向国际标准组织ECMAScript提交了21个标准一致性测试用例。